Replicating LLM-ForcedAligner (part 1)
Hello!
This is the first time that I wrote a “full” blogpost of anything. I have been wanting to write some blogpost about something that I am currently working on or some past project that I have done.
I am open to any feedback about my blogpost, please write a comment or send me an email at saya@akmal.dev!
Please note that I am not in any way a machine learning expert. This blogpost should contain some errors, please do let me know about it. Anyway, happy reading!
–
It is that time of the year again, where, I, for some reason have an interest on speech processing again. Luckily, I have more spare time this time around than last year, and able to do more funner things. One thing that I always wanted to do is build a large scale Indonesian speech-to-text (STT) dataset (1). While Indonesian language have a lot of speakers, the publicly available STT dataset is “smaller” when compared to English, Chinese, or any european language (french, germany, etc).
One of the ways to collect STT dataset is to find collections of audio and their respective subtitles or transcripts. Sometimes, the provided transcripts are available as text and actually transcribe the entire audio, which might have length ranging from tens of minutes to hours. This introduces a problem where STT dataset expect audios that are usually around 5 to 15 seconds (2), so there needs to be a way to split the long audio to 5-15 while having part of the long transcript align to its shorter audio.
What is Forced Alignment?
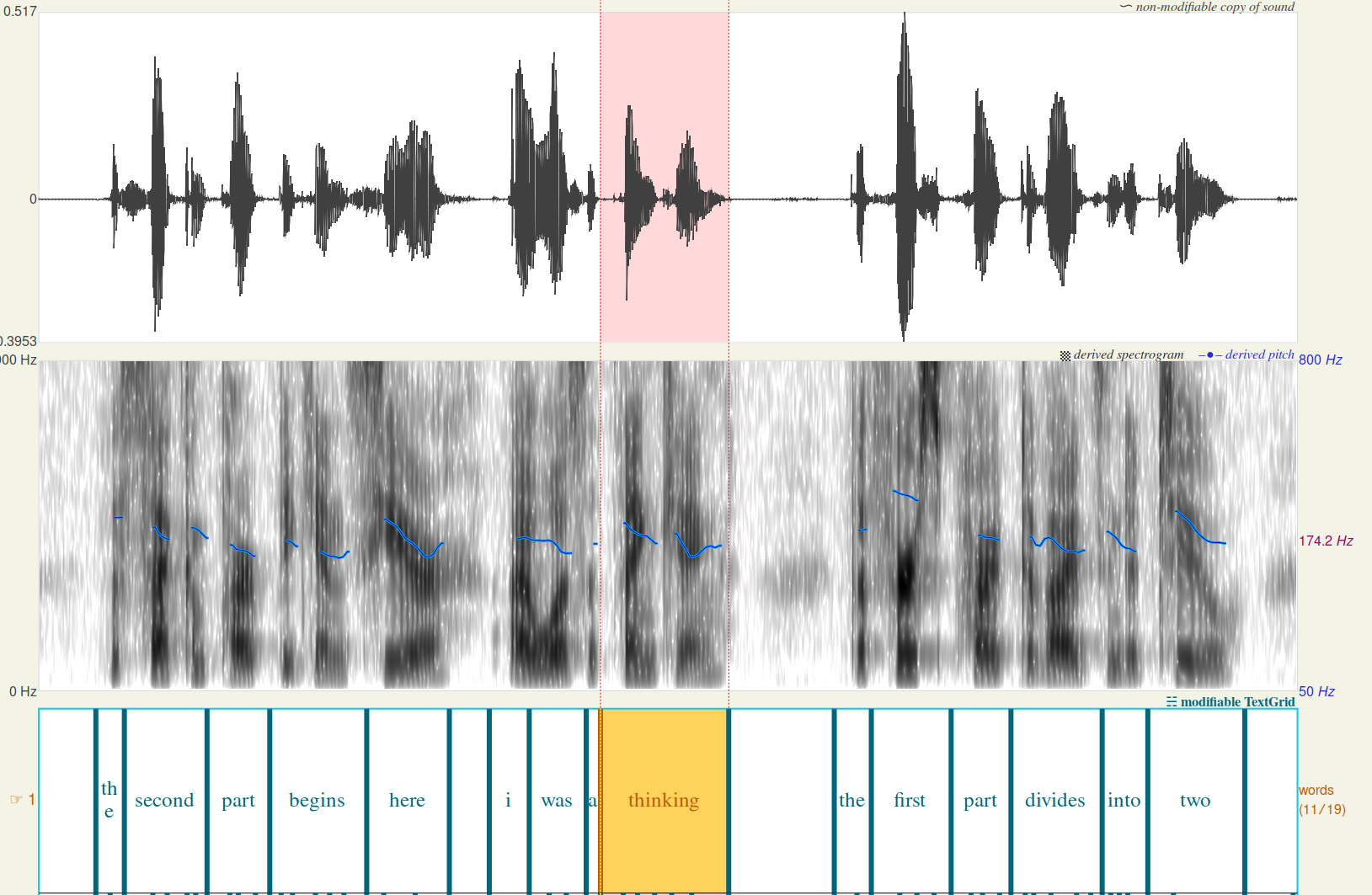
To create segments of audio and its transcript, you force align the audio to their transcript to generate timestamp for each word of transcript. For example I have a 5 second of audio and 3 word transcript. Force alignment will produce time of said foreach word. Similar to:
| Word | Start Time | End Time |
|---|---|---|
| I | 00:01.00 | 00:01.45 |
| Like | 00:02.03 | 00:02.90 |
| My | 00:03.30 | 00:03.78 |
Which can be visualized using Praat:
Force alignment method has existed for a while since 2017 and there have been new methods to do that. Montreal Forced Aligner is one of the most used forced aligners, it is based on Kaldi STT using HMM-GMM model to align audio to its phoneme representation. Newer methods like WhisperX combines Whisper transcription with a phoneme Wav2Vec2 model to generate its alignment.
What is Qwen’s LLM-ForcedAligner?
Recently Qwen team from Alibaba Cloud released Qwen3-ASR that consist of an STT/ASR model and a forced aligner. In the past, forced alignment methods are mostly based on STT outputs, where STT model generates “path” that can be used to align each word to their audio frames. In LLM-ForcedAligner, it did not work like this. This model is directly trained to align each word to their start and end timestamps.
LLM-ForcedAligner are based on a GPT-like model that works on token-level. So, how does it learn to force align if it works on token-level? Shouldn’t the audio model work on a mel-spectogram or a filterbank? To make a GPT model “learn” about audio we first need to convert it to “audio tokens”. Where each audio token represents an audio frames, which are a very short segment of audio usually around 80ms or even less.
In Qwen3-ASR family models, audio tokens are generated via an Audio Transformer (AuT) audio encoder. Audio encoder convert a full audios to sequences of tokens by doing downsampling the Fbank feature with 100Hz rate to 12.5 audio rate. Meaning 1 second of audio will generate 12.5 “audio tokens” [3].
After we are able to make GPT learn about audio, we can continue on how does LLM-ForcedAligner directly learn alignment. The way it is trained to predict which audio tokens do a word belongs to. For example, I have a 10s audio (10,000 ms) and the word “love” is said at milisecond of 240 until 800. The model are trained to predict that the word “love” start to appear on tokens of 3 and ends on tokens of 10.
To train the model to predict start and end token timestamp, LLM-ForcedAligner is structured in a similar way to usual GPT input. They structure its input following:
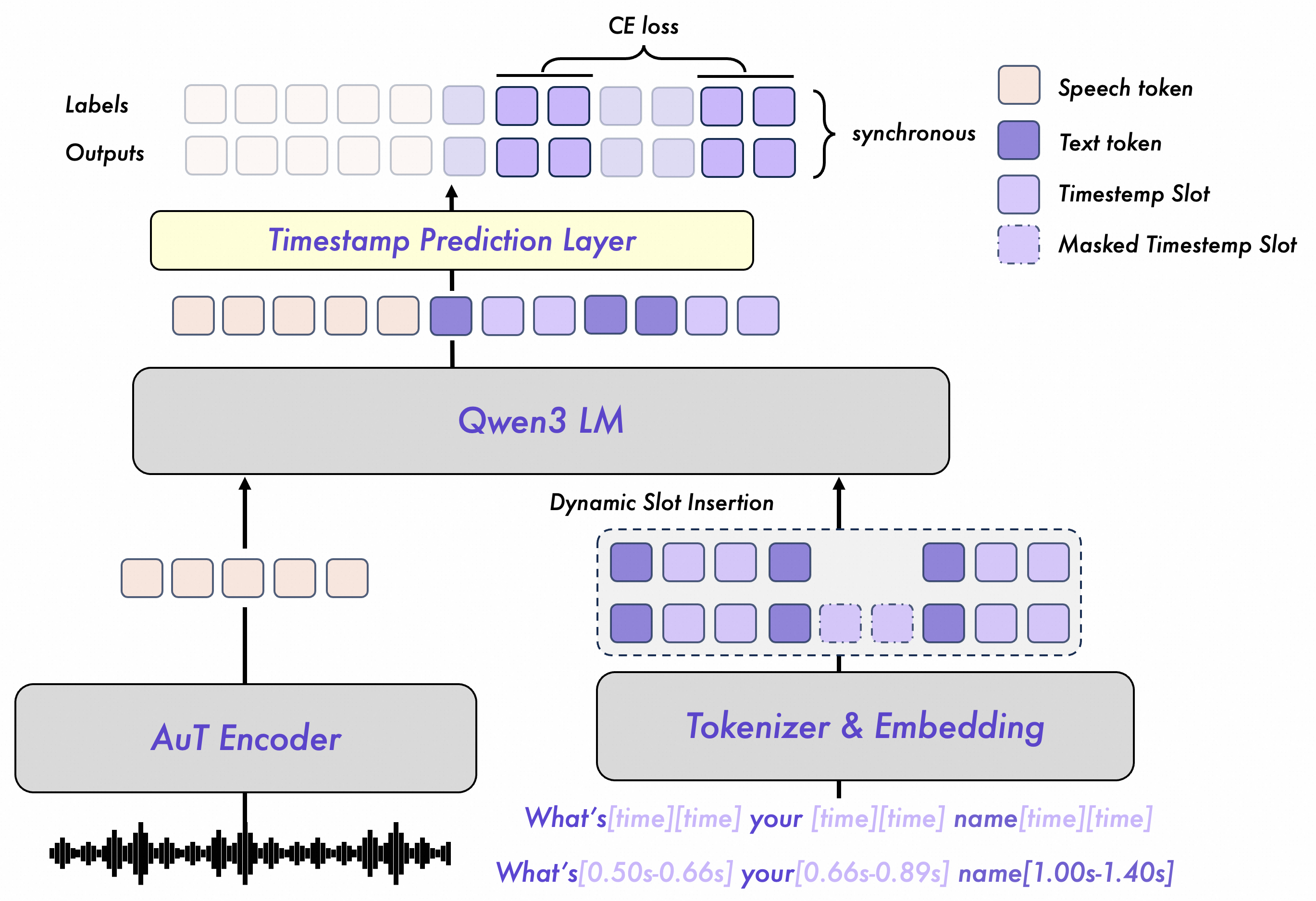
Input starts with the audio tokens and followed by its transcript, where each word get a “time slot” that will be used to represent start and end token timestamp.
It is that “time slot” that will be used as a marker for the model to learn forced alignment. Each time slot token attention state will be used to predict a sequence that represent indices of audio tokens. This prediction happens on Timestamp Prediction Layer which are a Linear head.
I would like to think this short post will be able to present how LLM-ForcedAligner works. There might be some part that I misunderstood, especially on audio encoding part.. Be sure to also read the original technical report by Qwen Team linked below!
–
Thank you for reading this weird thing. On part 2, I would like to write a simpler version of LLM-ForcedAligner that I can train without big GPU. It will use a simpler architecture and smaller/shorter data, and only focuses on English language.
Acknowledgement
I would like to thank Nangis for all the memes and funny videos. I would like to thank all my friends that directly and indirectly helping me have the courage to write and do all this. Including but not limited to ARP, BA, AF, HDD.
Resources and Citations
[1] B. Mu, X. Shi, X. Wang, H. Liu, J. Xu, and L. Xie, ‘LLM-ForcedAligner: A Non-Autoregressive and Accurate LLM-Based Forced Aligner for Multilingual and Long-Form Speech’, arXiv [cs.SD]. 2026.
[2] X. Shi et al., ‘Qwen3-ASR Technical Report’, arXiv [cs.CL]. 2026.
[3] J. Xu et al., ‘Qwen3-Omni Technical Report’, arXiv [cs.CL]. 2025.
[4] M. McAuliffe, M. Socolof, S. Mihuc, M. Wagner, and M. Sonderegger, ‘Montreal Forced Aligner: Trainable Text-Speech Alignment Using Kaldi’, in Interspeech 2017, 2017, pp. 498–502.
Footnotes
(1) There is already a large scale speech dataset from GigaSpeech team called GigaSpeech2 containing ~10k hours of speech. Soo my “dream” might not be as important as it is lol.
(2) This happens because you can’t fit a long audio in VRAM and if you are using a CTC-based STT model, your model might struggle to align the transcript to the respective audio frames.